“CMake is hard and our builds are a nightmare!” If that sounds familiar, you’re not alone. CMake has a reputation for being painful to use - but most of that pain comes from bad practices, not the tool itself.In this post, I’ll break down 7 of the most common CMake anti-patterns I see in real projects. These issues often creep in from legacy setups or lack of modern CMake knowledge, and they tend to slow teams down, cause frustration, and make build systems nearly unmaintainable.

Software development is an expensive business. Measured over the lifespan of a product, the cost of maintaining and changing the code over time often greatly outweighs the initial development cost. Successful software products nowadays often have lifespans measured in decades rather than years, and often they are kept under active development throughout the whole period. Evolving technology, fixing defects, adaptation to customer needs, or pressure from competition are common reasons why software needs change. In view of this, it is paramount that when designing software and writing code, you should optimize for reducing future cost of change first before anything else.
Managing dependencies in CMake is hard. It’s a common pain point for C++ developers, especially when working on multi-platform projects or with complex dependencies. The introduction of dependency providers in CMake 3.24 aims to simplify this process by allowing package managers like Conan to provide dependency information directly to CMake. Conan and CMake are already a powerful combination for managing C++ dependencies, and this new feature further enhances their integration. In this post, we’ll explore how to use Conan as a CMake dependency provider, making dependency management in CMake projects more seamless and efficient. A sample project can be found on my github account
In software development, the way we do planning plays a crucial role in determining the success or failure of a project or product. It’s a dance between trying to foresee every possible scenario and being agile enough to navigate uncertainties as they pop up. On a high level, two primary approaches dominate this landscape: preventive planning and corrective planning. While classical project management methodologies often favor preventive planning, the agile movement has brought corrective planning to the forefront, emphasizing adaptability and responsiveness.
Creating a clean library that has proper symbol visibility and installation instructions might sound difficult. However with CMake it is relatively straight forward to set up, even if there are a few things to consider. Actually creating creating a library is as simple as invoking the add_library() command and adding the sources to it. When it comes to setting up the installation instructions and symbol visibility properly there is a bit more to it. There are also some small, but useful things like defining the version compatibility of the library that make the life of developers a lot easier if done properly.

LLMs and AI make software development harder. Wait, what? Isn’t the whole point of AI to make writing code easier? Well, yes. But writing code is the easy part of software development. The hard part is understanding the problem, designing business logic and debugging tough bugs. And that’s where AI code assistants like copilot or chatgpt make our job harder, as they strip a way the easy parts of our job and only leave us with the hard parts and make it harder for new developers to master the craft of software development.

Empowering Teams is a key aspect to create high-performing teams in an agile setting. Ever since Extreme Programming was introduced into the world of software development this statement or a variety of it has been carried over to almost all agile frameworks. And there is a multitude of articles about how to create them. But what does “empowered” exactly mean? What are the minimum powers that a team needs to be able to be agile?
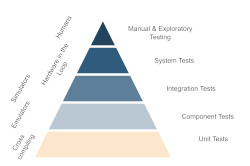
“Testing our software is difficult, because of the hardware involved”, is a common sentence when developing software for a specific hardware platform. Testing software that interacts closely with hardware indeed complicates the testing setup and in turn, often means that additional cost and effort are required. As the range of “embedded software” goes from low-level firmware running on a specific chip to software running on a specifically designed operating system with custom peripherals there is no one-size-fits-all solution to this. However, there are some strategies and principles that can help to make testing when easier and more effective.
CMake presets are arguably one of the biggest improvements in CMake since the introduction of targets in 2014. In a nutshell, CMake presets contain information on how to configure, build, test and package a CMake project and they are a tremendous help when managing different configurations for various compilers and platforms. Instead of fiddling with various command-line options, presets are stored in a JSON file and can be used to configure CMake with a single command. This article shows how to set up and organize and use them so they are most effective and easy to maintain.
If you build GUI applications with C++ and Qt, chances are that you have to create a mobile version of it. While the discussion, if Qt and C++ or the native Android SDK is the right technology to use is certainly worth a tought, there are situations where it makes sense to stick with Qt and C++. This article illustrates line by line how to build a C++/Qt application for android with CMake and how to pack it into an android APK.